1. 从对话框到操作系统级的智能体变革
1.1 人工智能交互范式的转移
当前,生成式人工智能(Generative AI)正处于一个关键的转型期,即从基于瞬时对话的“聊天机器人(Chatbot)”模式,向具有持久性、上下文感知能力和执行能力的“智能体(Agent)”模式演进。在早期的交互设计中,用户通过一个孤立的对话框(Chat Box)与大语言模型(LLM)进行交互,这种模式虽然降低了使用门槛,但也人为地切断了模型与用户工作环境(文件系统、浏览器、操作系统状态)之间的联系。
随着 GPT-5.1、Claude 4.5 Opus 等具备强推理能力模型的出现,以及 DeepSeek-V3.2、Qwen 3 等高性能开源模型的普及,桌面级应用开始经历一场深刻的架构重构。这种重构的核心目标是打破模型与应用之间的“空气墙”,让 AI 能够直接感知屏幕内容、读取本地文件、甚至操控鼠标和键盘。
本次调研选取的四个工具——Void Editor、BrowserOS、CherryStudio 和 MineContext——并非随意的组合,而是精准代表了开源社区在构建“桌面级 AI Agent”时的四种截然不同的架构哲学和演进方向:
- Void Editor(IDE 智能体化): 代表了垂直生产力工具的深度改造。它不满足于仅仅作为插件存在,而是通过 Fork 现有的 IDE(VS Code),从底层重构编辑器的行为,使其成为一个能够自主编写、调试代码的“开发者代理”。
- BrowserOS(浏览器智能体化): 代表了互联网入口的重塑。它挑战了传统浏览器的被动渲染模式,试图构建一个能够理解网页结构(DOM)、自动执行跨网页任务的“上网代理”。
- CherryStudio(模型编排与 RAG 中枢): 代表了通用大模型客户端的极致进化。它通过解耦“界面”与“模型”,构建了一个支持多模型并在本地运行检索增强生成(RAG)的“知识中枢”。
- MineContext(系统级感知与记忆): 代表了后台服务的智能化。它引入了“上下文工程(Context Engineering)”的概念,通过持续的屏幕感知和视觉理解,构建用户的“数字记忆”,并提供主动式的辅助。
1.2 开源与本地优先(Local-First)的战略意义
这四款工具的一个共同特征是其“开源”与“本地优先”的属性。在微软 Copilot、OpenAI ChatGPT Desktop 等闭源巨头试图垄断桌面入口的背景下,这些开源工具提供了一种基于“用户主权”的替代方案。
- 数据主权与隐私: 闭源 Agent 通常需要将用户的屏幕截图、代码库或文档上传至云端进行处理,这在企业合规(如 GDPR、SOC2)和个人隐私保护方面存在巨大风险。本次调研的工具均支持或默认采用“直连模式(Direct-to-Provider)”或“本地推理(Local Inference)”,确保敏感数据不经过中间商服务器 1。
- 架构的模块化: 它们均支持接入 Ollama、vLLM 等本地推理框架,使得算力可以下沉到用户边缘设备。这种架构不仅降低了 API 调用成本,还使得在无网(Air-Gapped)环境下运行智能体成为可能。
- 协议的标准化: 随着模型上下文协议(Model Context Protocol, MCP)的兴起,这些工具不再是孤岛。调研显示,Void Editor 和 BrowserOS 均已开始探索或支持 MCP,预示着未来桌面 Agent 将形成一个互联互通的生态系统 1。
本文将从技术架构、功能特性、隐私机制及生态位四个维度,对这四款工具进行详尽的拆解与对比分析。
2. 垂直领域的重构:Void Editor 与 IDE 的智能体化
Void Editor 是当前 AI 辅助编程领域中,试图通过开源路径复刻甚至超越 Cursor 体验的代表性项目。它选择了一条最艰难但也最具潜力的道路:Fork VS Code。这不仅是一个技术选择,更是一种对“编辑器即 Agent”理念的坚持。
2.1 架构基础:为何必须 Fork VS Code?
在 AI 编程助手的早期阶段,大多数工具(如 GitHub Copilot、Continue)都是以 VS Code 插件(Extension)的形式存在的。然而,插件架构存在天然的局限性:
- UI 限制: 插件无法自由修改编辑器的核心 UI(如 Diff 视图、终端集成方式),导致 AI 生成的代码往往只能以侧边栏对话或简单的 Ghost Text 形式展现。
- 上下文访问受限: 插件对文件系统的访问权限受限于 VS Code 的沙盒机制,且难以获取编辑器内部的完整状态(如光标历史、LSP 语义信息)。
- 延迟问题: 插件必须通过 VS Code API 进行通信,增加了交互延迟。
Void Editor 通过 Fork VS Code 的代码库(基于 1.99.0+ 版本),直接修改了编辑器的渲染层和逻辑层 1。这种“原生集成”使得 Void 能够实现插件无法做到的功能,例如 Fast Apply(快速应用)和 Agent Mode(代理模式)。
2.1.1 混合架构:ML 集成层
Void 的架构可以被描述为一种“混合架构”,它保留了 VS Code 传统的非 ML 基础设施(文件管理、扩展宿主、调试器),但引入了一个平行的 ML 集成层(ML Integration Layer) 6。
- VoidModelService: 这是 Void 的核心服务,负责管理大语言模型的生命周期。不同于简单的 API 调用,该服务维护了模型对象的引用,防止在高频交互中上下文被过早销毁。
- LLMMessageService: 作为中枢神经系统,它协调所有 AI 交互,无论是来自侧边栏的对话,还是来自编辑器内部的内联编辑(Ctrl+K)。
2.2 核心特性剖析:超越自动补全
2.2.1 Agent Mode(代理模式)与 Gather Mode(采集模式)
Void Editor 将 AI 的能力分为了三个层级:Chat(对话)、Gather(采集)和 Agent(代理)。其中,Agent Mode 是其作为“桌面级 Agent”的核心体现。
- 自主决策循环: 在 Agent Mode 下,Void 不再是被动等待用户指令的工具,而是一个具备“思考-行动-观察”循环的智能体。它可以自主决定搜索哪些文件、读取哪些代码片段、甚至执行终端命令来验证代码 1。
- 权限分级: 为了平衡自动化与安全性,Void 引入了 Gather Mode。这是一种受限的 Agent 模式,允许 AI 搜索和读取代码库以回答复杂问题,但禁止其修改文件或执行破坏性操作 1。这种设计体现了对开发者“控制权”的尊重。
- MCP 工具集成: Void 的 Agent Mode 集成了模型上下文协议(MCP),这意味着它不仅可以操作代码,还可以调用外部工具。例如,它可以连接到数据库查询 MCP 服务器,或者调用浏览器 MCP 服务器来查阅最新的 API 文档 1。
2.2.2 Fast Apply 与流式 Diff
在传统的 AI 编程助手中,当 LLM 生成大段代码时,用户必须等待生成完成,然后手动点击“接受”。Void 引入了 Fast Apply 机制。
- 技术原理: Void 优化了 AI 生成代码的应用过程,即使是针对 1000 行以上的大文件,也能实现毫秒级的应用速度 1。这可能涉及到对 Diff 算法的底层优化,以及直接操作编辑器的 TextBuffer,而非通过高层的 API。
- 视觉化 Diff: 得益于 Fork 的优势,Void 将 Diff 视图直接嵌入到了代码编辑器中,而非弹出一个新的窗口。用户可以看到 AI 的修改建议以绿色/红色高亮实时流式呈现在代码行间,提供了极佳的开发者体验(DX) 7。
2.2.3 Checkpoints(LLM 变更检查点)
AI 生成代码的一个主要痛点是“幻觉”导致的破坏。Void 引入了 Checkpoints 机制,专门用于追踪 LLM 的变更 1。
- 独立于 Git: 这个版本控制系统是独立于 Git 存在的。它记录了每一次 AI 对话导致的代码库状态快照。这意味着用户可以随意让 Agent 尝试激进的重构,如果结果不满意,可以一键回滚到 AI 介入前的状态,而不会污染 Git 的提交历史。
2.3 隐私与连接性:去中心化的胜利
Void Editor 的核心卖点之一是 “切断中间商(Cut out the middleman)” 1。
- 直连架构: 与 Cursor 或 Windsurf 不同,Void 不会将其用户的代码请求路由通过自己的私有后端服务器。相反,它直接从用户的客户端发起对 Anthropic、OpenAI 或 Google 的 API 请求。
- 隐私意义: 这种架构确保了 Void 的开发团队(Glass Devtools)无法窥探用户的代码或 Prompt。这对于处理专有代码的企业用户至关重要。
- 本地模型支持: Void 对 Ollama、vLLM 等本地推理框架的一流支持,使得它能够在完全断网(Air-Gapped)的环境下工作,这是闭源竞品难以企及的优势 6。
2.4 生态挑战与未来展望
尽管架构先进,Void Editor 面临着巨大的维护挑战。Fork VS Code 意味着必须时刻跟进微软上游代码库的更新,这是一项繁重的工作。调研资料显示,项目的主仓库曾一度“暂停(paused)”以探索新的 AI 编码理念 7,这引发了社区对其长期可持续性的担忧。然而,近期 Beta 版的密集更新(支持 Claude 3.7、Grok 3 等前沿模型)表明项目依然活跃 1。
未来,Void Editor 可能会演变成一个更广泛的“AI 原生 IDE 框架”,不仅服务于 JavaScript/Python 开发者,而是通过 MCP 协议成为连接本地所有开发工具(数据库、云资源、文档)的通用控制台。
3. 浏览器Agent:BrowserOS 的原生智能架构
如果说 Void Editor 是代码世界的 Agent,那么 BrowserOS 则是万维网的 Agent。它不仅是一个浏览器,更是一个运行环境,一个专为 AI Agent 设计的操作系统。
3.1 重新定义浏览器:从渲染引擎到执行环境
传统的 Web 浏览器(Chrome, Firefox)设计初衷是供人类阅读和交互。然而,AI Agent 在浏览网页时有着完全不同的需求:它需要结构化的数据而非像素,需要 API 级的交互而非鼠标点击。
BrowserOS 基于 Chromium 进行 Fork,构建了一个原生支持 AI Agent 的环境。
- 技术栈构成: 项目代码中 C++ 占比 49.4%,Python 占比 35.4%2。
- C++ 层: 负责底层的 Chromium 渲染引擎、网络栈和安全性,保持与现代 Web 标准的兼容性。
- Python 层: 这是 BrowserOS 的独特之处。Python 是 AI 开发的通用语言,BrowserOS 将 Python 环境嵌入或紧密集成到浏览器中,作为 Agent 的运行后端。这意味着用户可以直接用 Python 编写脚本来控制浏览器,或者运行基于 Python 的复杂 Agent 框架(如 LangChain, AutoGPT)。
3.2 智能体与 DOM 的交互机制
BrowserOS 的核心能力是让 AI “理解”网页。
- DOM 解析与语义化: 普通的 HTML 对于 LLM 来说往往过于冗长且充满噪音(广告、样式代码)。BrowserOS 内部可能实现了一套机制,将复杂的 DOM 树转化为精简的、语义化的表示(Accessibility Tree 或简化版 HTML),供 LLM 消费 5。
- 自然语言驱动的自动化: 用户无需编写 Selenium 或 Puppeteer 脚本,只需输入自然语言指令(例如:“登录我的亚马逊账户,查找过去一年购买的所有书籍,并将其导出为 CSV”)。BrowserOS 的内置 Agent 会将这一指令分解为一系列浏览器动作(点击、输入、滚动、抓取)5。
- 本地运行: 这些 Agent 运行在本地浏览器进程中,而非云端。这意味着用户的 Session Cookie、LocalStorage 数据不需要发送给第三方服务器,极大地保护了隐私 10。
3.3 界面创新:Split View(分屏视图)
为了适应 AI 辅助浏览的场景,BrowserOS 引入了 Split View 界面 5。
- 人机协作: 左侧是传统的网页视图,右侧是 AI Agent 的交互面板(支持 ChatGPT, Claude, Gemini 等)。
- 上下文同步: 右侧的 AI 模型能够实时读取左侧网页的内容。用户可以随时选中网页上的一段文字,拖拽到右侧让 AI 解释,或者让 AI 自动总结当前页面的核心内容。这种交互模式比传统的“复制-粘贴”要高效得多。
3.4 MCP 服务器:浏览器的能力输出
BrowserOS 的一个战略性功能是它不仅是一个客户端,还可以作为一个 MCP Server 2。
- 跨应用调用: 通过 MCP 协议,BrowserOS 将其浏览能力暴露给系统中的其他 Agent。例如,你在 Void Editor 中写代码时遇到一个报错,Void Editor 的 Agent 可以通过 MCP 调用 BrowserOS,在后台静默搜索 StackOverflow,提取解决方案,并返回给编辑器。
- 生态位: 这将 BrowserOS 定位为“本地 AI 操作系统”中的“Web 接口服务”,使其成为其他工具获取网络信息的通用网关。
3.5 竞品对比与市场定位
BrowserOS 将自己定位为 ChatGPT Atlas 或 Perplexity Comet 的隐私优先替代品 2。
- Atlas/Comet 模式: 用户的浏览历史和交互数据被上传到云端,用于构建用户的云端记忆。
- BrowserOS 模式: 所有浏览历史、Agent 执行日志均存储在本地。用户可以拥有强大的搜索和自动化能力,而无需牺牲隐私。这对于金融分析师、调查记者或企业研究员等对数据敏感的人群具有极大的吸引力。
4. 模型编排与知识中枢:CherryStudio 的通用客户端范式
与 Void 和 BrowserOS 专注于特定领域(代码、Web)不同,CherryStudio 致力于解决“模型碎片化”和“知识孤岛”的问题。它是一个通用的、桌面级的 AI 工作台。
4.1 统一模型管理(Unified Model Management)
当前的 LLM 市场呈现出极度的碎片化:OpenAI 的 GPT-4o 擅长逻辑,Anthropic 的 Claude 3.5 Sonnet 擅长代码,DeepSeek-R1 擅长推理,而 Google Gemini 1.5 Pro 拥有超长上下文。
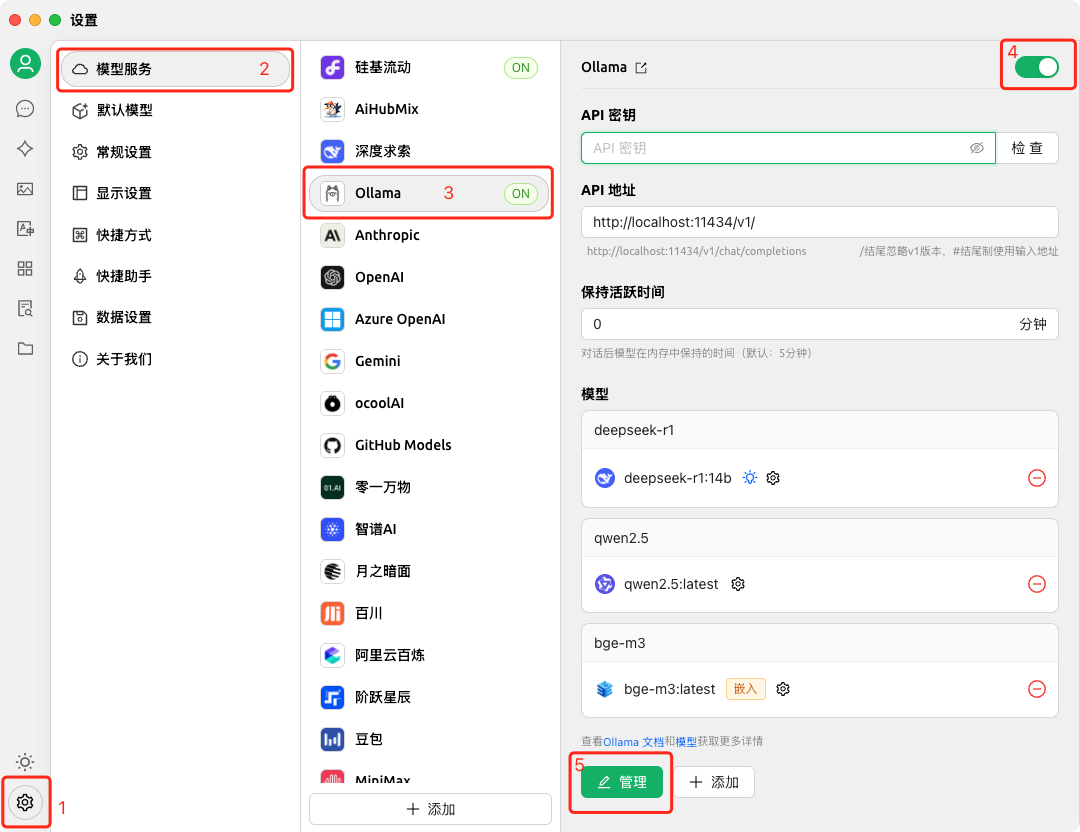
CherryStudio 提供了一个统一的控制台,允许用户同时配置和管理所有这些模型 3。
- 多模型并联: 用户可以在同一个对话窗口中同时通过多个模型发送相同的 Prompt,对比其输出效果。这对于提示词工程(Prompt Engineering)和模型选型非常有价值。
- 混合部署: 支持同时连接云端 API(OpenAI, SiliconFlow)和本地服务器(Ollama, LM Studio)。企业用户可以利用这一点,将敏感任务路由到本地模型,将普通任务路由到廉价的云端模型,实现成本与安全的平衡 12。
4.2 本地 RAG 与知识库构建
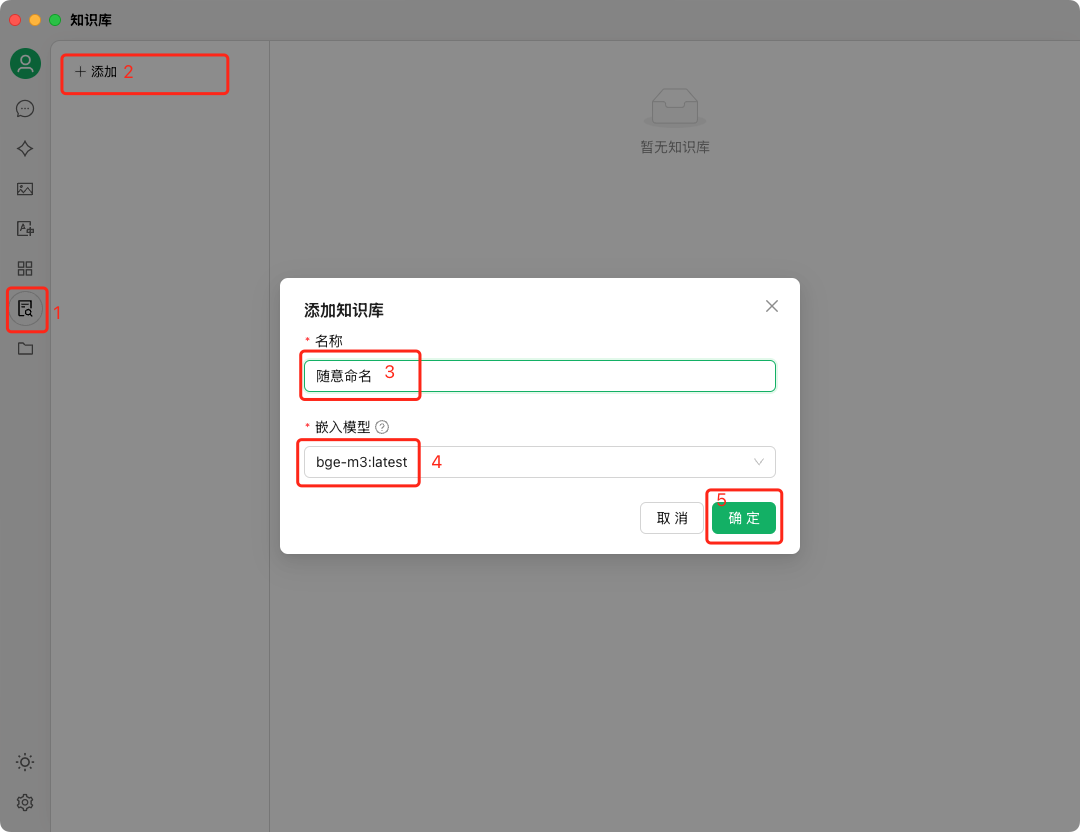
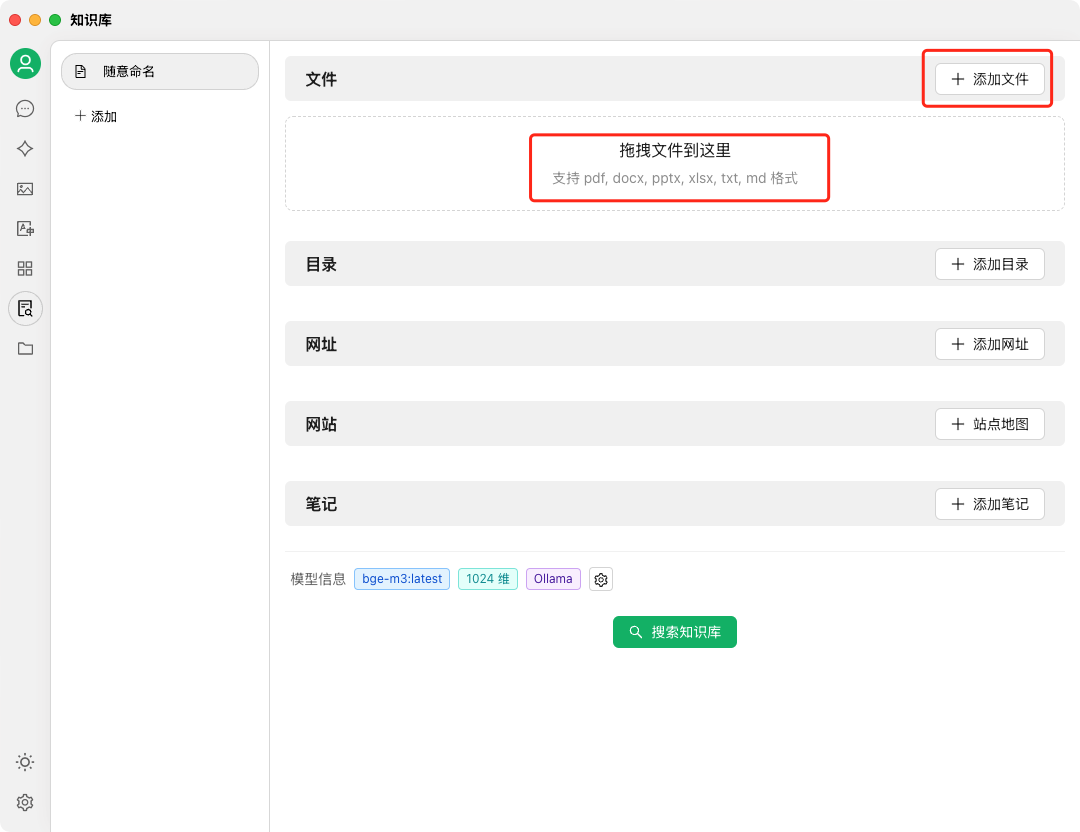
CherryStudio 的核心竞争力在于其强大的 本地 RAG(检索增强生成) 能力,它允许用户构建“第二大脑” 12。
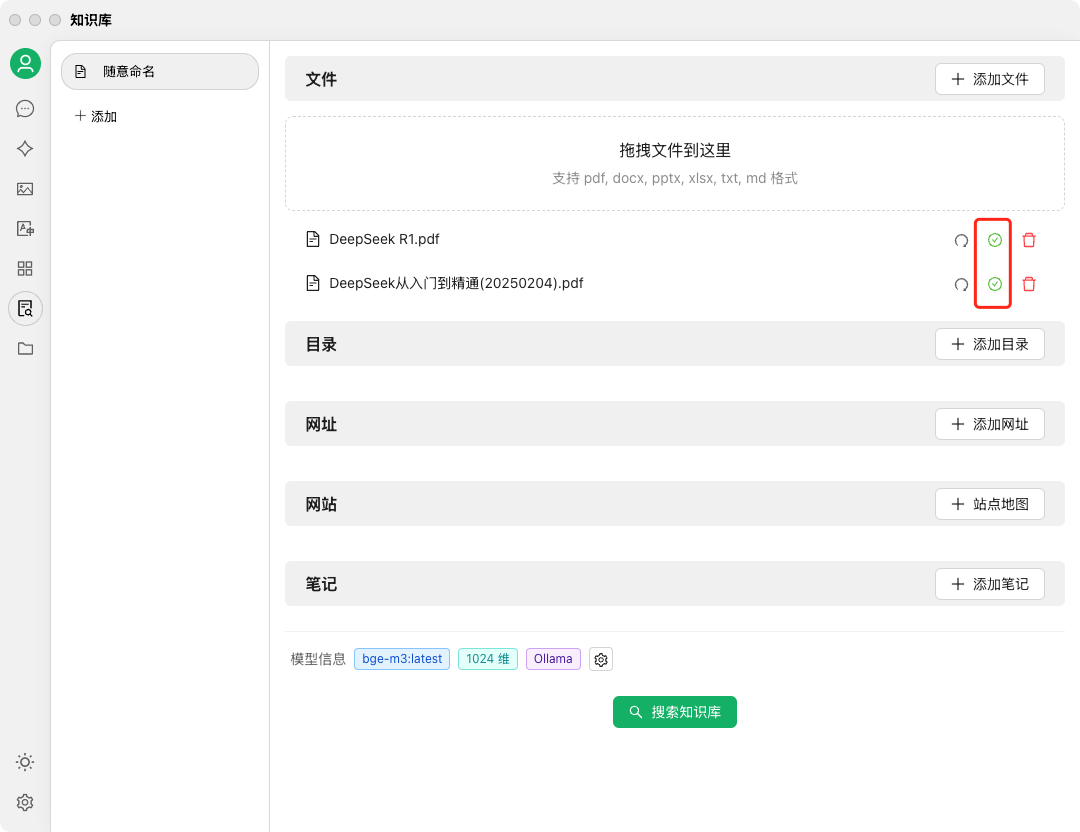
- 多格式支持: 支持导入 PDF、DOCX、PPTX、TXT、Markdown 等多种格式的文档,甚至支持 WebDAV 同步和 URL 抓取 11。
- 本地向量化架构:
- 嵌入模型(Embedding Model): 用户可以选择使用本地的嵌入模型(如
bge-m3)通过 Ollama 运行,或者使用云端嵌入 API。这意味着向量化过程可以完全在本地完成,无需上传文档内容 13。 - 向量数据库: 虽然调研材料未明确指出其内置的向量数据库品牌(可能是 SQLite-vec, Chroma, 或 LanceDB),但从其“无需环境配置、开箱即用”的特性 11 推断,它极有可能使用了嵌入式的向量存储方案(如基于 SQLite 的扩展或轻量级文件型向量库),而非需要独立部署的服务器型数据库。
- 嵌入模型(Embedding Model): 用户可以选择使用本地的嵌入模型(如
- 检索与生成: 当用户在 CherryStudio 中提问时,系统会首先在本地向量库中进行语义检索,找到相关的文档切片,然后将这些切片作为上下文注入到 LLM 的 Prompt 中。这一过程完全透明,且支持引用溯源。
4.3 助手商店与即插即用的 Agent
为了降低普通用户的使用门槛,CherryStudio 引入了 “助手(Assistant)” 的概念 11。
- 预配置角色: 内置了 300+ 个预配置的 AI 助手,涵盖翻译、写作、编程、法律咨询等场景。每个助手本质上是一个精心调试的 System Prompt 加上特定的模型参数设置。
- 自定义与分享: 用户可以创建自己的助手,甚至通过导入/导出功能与团队共享。这使得企业可以将内部的最佳实践固化为一个个 AI 助手,分发给员工使用。
4.4 技术栈与跨平台特性
CherryStudio 是一个基于 Web 技术栈构建的桌面应用(94.5% TypeScript),推测使用了 Electron 或 Tauri 框架 11。这保证了它在 Windows、macOS 和 Linux 上的一致体验。其界面设计现代化,支持亮色/暗色主题和透明窗口,符合现代 SaaS 工具的审美标准。
5. 操作系统级的感知记忆:MineContext 与上下文工程
MineContext 代表了 AI Agent 的终极形态之一:隐形且全知。它不是一个等待用户打开的工具,而是一个潜伏在后台的操作系统守护进程,通过“看”来理解用户。
5.1 上下文工程(Context Engineering)的哲学
MineContext 提出的核心概念是 “上下文工程”。它认为,AI 能够提供的帮助质量,取决于它所能获取的上下文的丰富程度。
其架构围绕数据的全生命周期展开:捕获(Capture) -> 处理(Processing) -> 存储(Storage) -> 检索(Retrieval) -> 消费(Consumption) 4。
- 被动感知: 与 CherryStudio 需要用户手动上传文档不同,MineContext 通过 屏幕录制(Screen Monitor) 自动收集信息。它以 P0 级优先级支持屏幕截图,未来计划支持多模态数据(文档、代码、外部应用数据) 4。
5.2 视觉语言模型(VLM)驱动的数字记忆
MineContext 的核心技术壁垒在于如何从视频流中提取结构化信息。
- OCR 与 VLM: 它利用 OCR(光学字符识别)技术提取屏幕上的文字,并结合视觉语言模型(如
Doubao-Seed-1.6-flash或 OpenAI Vision)来理解屏幕内容的语义 4。例如,它不仅能识别出屏幕上有“会议”二字,还能理解这是一个日历应用中的待办事项。 - 双模型架构: 为了平衡成本与性能,MineContext 建议用户配置两个模型:一个视觉模型用于理解截图,一个嵌入模型(如
Doubao-embedding-large)用于生成向量索引 4。
5.3 隐私优先的数据架构
由于涉及极其敏感的屏幕数据,MineContext 采取了最为严格的 “本地优先(Local-First)” 策略。
- 本地存储路径: 所有截图、OCR 文本、向量索引数据均存储在用户的本地目录
~/Library/Application Support/MineContext/Data下 4。 - 数据隔离: 默认情况下,数据不会上传到云端。即使用户使用云端模型 API 进行分析,传输的也是经过处理的切片数据,且支持 API Key 掩码等安全措施 15。
- 后端架构: MineContext 采用了 Electron 前端 + Python 后端的架构。Python 后端负责繁重的图像处理和向量计算任务,这使得它能够利用 Python 丰富的 AI 生态库(如 PyTorch, ChromaDB 等) 4。
5.4 主动式服务:从 Ask 到 Push
MineContext 的交互模式是 “主动交付(Proactive Delivery)” 4。
- 遗忘与回响: 用户启动录制后,可以“忘记它(Forget it)”。系统会在后台静默分析,然后主动向用户推送“每日摘要”、“待办事项清单”或“活动回顾”。
- 场景举例: 当用户在一天结束时打开 MineContext,它会自动生成一份日报:“你今天上午花了 3 小时在 VS Code 中编写 Python 代码,下午浏览了 20 个关于 RAG 架构的网页,并在 Notion 中记录了 5 条笔记。” 这种能力对于量化自我(Quantified Self)和生产力分析具有革命性意义。
6. 核心架构维度的横向对比与技术哲学
为了更清晰地展示这四个工具的定位差异,本节提供详细的横向对比分析。
6.1 技术栈与架构对比表
| 特性维度 | Void Editor | BrowserOS | CherryStudio | MineContext |
| 核心定位 | IDE Agent (生产力/代码) | Browser Agent (信息获取/自动化) | Hub Agent (管理/RAG) | Memory Agent (感知/后台) |
| 基础架构 | VS Code Fork (Electron) | Chromium Fork (C++) + Python | 通用客户端 (Electron/TypeScript) | 桌面应用 (Electron + Python Backend) |
| 智能来源 | 代码库 + 编辑器状态 | 网页 DOM + 浏览会话 | 本地知识库 (Docs) + 多模型 API | 屏幕视觉流 (Screenshots) |
| 交互模式 | 主动 (Active) 编写代码、执行终端 | 主动 (Active) 点击网页、抓取数据 | 被动 (Reactive) 问答、检索 | 观察/主动 (Proactive) 后台记录、主动推送 |
| 数据存储 | 文件系统、Git | 浏览器 Profile、本地日志 | 本地向量库 (SQLite/BGE) | 本地数据目录 (SQLite/Chroma) |
| RAG 实现 | 代码库索引 (FIM/Embedding) | 网页内容实时解析 | 显式文档上传与向量化 | 屏幕历史视觉索引 |
| MCP 支持 | Client & Host (调用工具,也能被调用) | Server (作为工具被调用) | Client/Server (计划中/部分支持) | Context Source (潜在的上下文源) |
6.2 “锚点”理论:智能体的根基
这四个工具揭示了构建桌面 Agent 的四个不同“锚点(Anchors)”:
- Void 锚定于“文件(Files)”: 它的智能建立在对项目文件结构和代码逻辑的理解之上。
- BrowserOS 锚定于“链接(Links)”: 它的智能建立在对万维网图谱和 DOM 结构的理解之上。
- CherryStudio 锚定于“文档(Documents)”: 它的智能建立在用户显式构建的知识库之上。
- MineContext 锚定于“时间流(Timeline)”: 它的智能建立在用户行为的时间序列和视觉历史之上。
未来的理想桌面 AI 操作系统,应当是这四个锚点的融合体。
7. 隐私安全、本地化与企业级落地的挑战
随着 AI Agent 从云端下沉到桌面,安全边界也随之改变。
7.1 “中间人攻击”与直连模式的安全性
Void 和 BrowserOS 均强调 “去中间人化”。虽然这避免了平台方的数据窃取,但也带来了新的风险:
- API Key 管理: 用户需要自行管理 OpenAI 或 Anthropic 的 API Key。如果本地机器中了木马,这些 Key 可能被窃取。MineContext 通过 UI 层的 Key 掩码和加密存储来缓解这一风险 15。
- 恶意 Agent 风险: 如果 Void 的 Agent Mode 被赋予了过高的权限(如终端执行权),恶意的 Prompt Injection 可能诱导 Agent 执行
rm -rf /或上传私钥。因此,Void 引入 Gather Mode(只读模式)作为一种安全屏障是非常必要的架构设计 1。
7.2 企业级合规与 Air-Gapped 环境
对于金融、军工、医疗等高敏感行业,这些开源工具提供了闭源 SaaS 无法提供的解决方案——物理隔离(Air-Gapped)部署。
- 全链路本地化: 结合 Ollama 运行 Llama 3 或 DeepSeek-Coder,配合 CherryStudio 的本地 Embedding 模型,企业可以构建一个完全断网的 AI 工作流。数据从产生(MineContext 录屏)、处理(Void 编写代码)、检索(CherryStudio RAG)到执行(BrowserOS 内部网自动化),没有任何比特流出局域网。
- 审计与溯源: 开源特性允许企业对代码进行审计,确保没有隐藏的遥测代码,这对于通过 SOC2 或 ISO27001 认证至关重要。
8. 结论:走向融合的本地 AI 操作系统
通过对 Void Editor、BrowserOS、CherryStudio 和 MineContext 的观察,我们可以清晰地看到桌面级开源 AI Agent 的演进脉络。它们不再是简单的“套壳”应用,而是各自领域的深度重构者。
- 工具的专业化与深耕: Void 证明了通用编辑器无法满足 AI 编程的需求,必须进行底层改造;BrowserOS 证明了浏览器需要为 Agent 而非仅为人设计。
- 协议的互联与生态化: 模型上下文协议(MCP) 将是未来的关键。我们预见,Void 将不再需要自己写网页抓取代码,而是直接调用 BrowserOS 的 MCP 接口;CherryStudio 将不再只是一个聊天窗口,而是成为调度 Void 和 MineContext 的中央指挥塔。
- 本地智能栈(Local Intelligence Stack)的成型:
- 底层算力: Ollama / vLLM / NVIDIA TensorRT
- 记忆与索引层: SQLite-vec / Chroma (由 MineContext/CherryStudio 维护)
- 感知与执行层: BrowserOS (Web) / Void (Code) / System API
- 交互编排层: CherryStudio / MCP
对于开发者和企业而言,现在的选择不再是“是否使用 AI”,而是如何组合这些开源模块,构建一个既强大又完全受控的“私人数字员工”。这四款工具,正是构建这一未来的基石。