1月
2024-01-01 20:19:02
对甜品的最高评价是不太甜 对男人的最高评价是不太男
2024-01-02 12:02:27
一些景点有了新的装修;
2024-01-02 12:05:16
元旦假期日均出入境人次恢复到2019年水平
2024-01-02 18:56:09
卫视中文台、卫视电影台、星卫HD电影台、星卫娱乐台停播
2024-01-04 00:00:48
每半个月领到的WLD,转到CEX卖掉,然后U转到OneKeyCard(这一步有手续费)就能在国内支付使用了……
2024-01-04 15:05:33
Pascal、Euler 和 Oberon 等语言的作者和合作者 Niklaus Wirth 于 2024 年 1 月 1 日去世,享年 89 岁。Niklaus Wirth 于 1934 年 2 月 15 日出生于瑞士,先后任教于斯坦福、苏黎世大学、苏黎世联邦理工学院,曾在施乐帕洛阿尔托研究中心进修两年。他是 Algol W 、Modula、Pascal、 Modula-2、Oberon 等语言的主设计师,是 Euler 语言的发明者之一。1984 年他因在编程语言上的贡献而获图灵奖。他亦是Lilith电脑和Oberon系统的设计和执行队伍的重要成员。
2024-01-05 18:49:05
Introducing http://aoyo.ai – the new AI search
This is an AI search product designed for everyone.
-Based on the latest RAG technology, it allows you to search foreign language content on the internet in your native language, and the AI will summarize and respond in your native language.
-No ads, no content censorship, supporting traditional search commands like site/filetype/inurl, and can replace daily web searches.
2024-01-07 10:55:40
《繁花》的电视频道播出时间:https://www.tvmao.com/drama/YG0jXGVl/playingtime
2024-01-08 17:32:56
做出海工具不要用国内域名注册商和dns,godaddy+cloudflare+github+vercel完事
2024-01-08 22:22:29
Vision Pro来了! 1/19开始预订,2/2美国上市
2024-01-08 23:32:45
元梦之星做得比蛋仔派对精美
2024-01-11 01:00:39
单曲循环一首low歌,明年的年度听歌报告不会有它吧
2024-01-11 01:21:17
我的 #2023年度产品 :ChatGPT、Midjourney、Raycast、HomeAssistant、aoyo.ai
2024-01-11 09:09:12
Apple Music家庭版涨价到17元/月
2024-01-11 09:23:40
一觉醒来:
2024-01-11 11:47:31
微信AI将会在今天微信公开课PRO上亮相
2024-01-11 16:54:00
实体产品:HappyRain碳纤维伞、摩飞便携电热水杯、SteamDeck、魅族myvu眼镜、添添闺蜜机
2024-01-13 19:27:18
赖萧配得票率已经超过40%
2024-01-15 20:02:24
瑙鲁与台湾断交,ROC邦交国只剩12个了
2024-01-19 19:29:01
冬青奥会在韩国江原道
2024-01-24 12:15:54
感谢流感疫苗的保护
2024-01-24 15:25:40
商业航天发展迅速,火箭发射的成本会越来越低。
2024-01-25 20:51:22
焦点访谈关注了人工智能(发展新质生产力系列报道)
2月
2024-02-01 10:20:35
对他人大段话语的引用,只用在每一段开头用左双引号。
2024-02-08 12:34:39
今年春节档前三预测:《热辣滚烫》《飞驰人生2》《第二十条》
2024-02-16 16:05:13
活到老,学到老。
2024-02-17 09:17:06
九牛迁到深圳改名新鹏城了,没能实现成都德比(虽然中甲时期有过)
2024-02-18 08:36:11
sora可以帮助电影创作者rapid prototype
2024-02-23 22:31:58
看了几集《小敏家》,剧中的装修风格不错。
2024-02-29 00:03:22
四年一次的一天。
3月
2024-03-06 15:23:12
视频生成今年应该会大跃进
2024-03-09 20:17:54
宽屏(16:9)HD视频是2010年左右普及的。
2024-03-10 13:05:08
United Nations Relief and Works Agency for Palestine Refugees “联合国近东巴勒斯坦难民救济和工程处” 或者简称为“近东救济工程处” 为什么官方中文名带有“近东”二字
2024-03-11 19:45:30
短跑第4道是卫冕道。卫冕冠军通常被安排在第4道。
2024-03-13 21:30:48
今年还是拜登vs川普
2024-03-15 18:09:26
看到一个新品牌和新品类:盖狮可吸果泥
2024-03-17 22:11:34
Suno出现之后,音乐工业会有大的变化吧
2024-03-27 17:52:11
小米SU7的电机研发还是砸了重金的。
4月
2024-04-05 20:37:13
保持对世界的好奇心
2024-04-07 19:22:45
小米SU7的广告视频是在外滩拍的
2024-04-13 21:04:09
原来民国时期就有证券市场。
2024-04-16 18:58:33
奥运火炬传递开始了。
2024-04-25 20:31:20
神舟十八号任务,成都人叶光富担任01指令长。上一次是神十三,这次任务完成后他在太空的累计时长可能会超过一年。
5月
2024-05-02 17:40:28
殷墟遗址在河南安阳市境内
2024-05-06 20:12:56
龟兹 和 虚与委蛇,以前读错了。
2024-05-07 19:25:10
M4 iPadPro 13寸,比Pencil还薄
2024-05-20 21:03:44
深圳有数字人民币硬钱包申领自助机了
2024-05-22 18:47:22
中华民国四个字出现在了央视
6月
2024-06-05 09:22:45
支付宝小荷包产品做得不错
2024-06-13 20:09:37
今年3个热播剧的片尾曲都是周深唱的
2024-06-14 23:47:02
欧洲杯揭幕战在安联球场,东道主德国的主场也是拜仁慕尼黑的主场
2024-06-22 19:34:50
在欧洲杯赛场的场边广告牌看到比亚迪的子品牌:方程豹
7月
2024-07-07 20:28:12
“垸”的意思是湖区大坝围合的陆地
2024-07-10 08:05:36
欧洲杯半决赛和美洲杯半决赛碰到了一起
2024-07-12 18:53:29
上半年新能源汽车占有率已达33.5%
2024-07-14 19:40:11
Trump被枪击后振臂一呼的形象刻在了历史中。
2024-07-16 15:09:14
伏天开始了,听到了更近的蝉鸣。
2024-07-26 16:08:24
进入奥运时间!
2024-07-28 04:02:44
21年之后有了cctv16奥林匹克频道,这次奥运会期间cctv5台标都不变成cctv奥运五环了
2024-07-29 07:58:21
用Termius替代了Transmit
2024-07-30 08:08:08
https://www.aminer.cn
8月
2024-08-01 10:48:32
deepseek模型背后是幻方,一个做量化交易的金融巨头,合理。
2024-08-05 08:36:44
李政道去世了
2024-08-06 00:50:58
巴黎奥运冲浪比赛是在大溪地(法属)举行的。
2024-08-06 00:56:23
原来Apple Intelligence要求iPhone 15 Pro是因为端侧大模型占用运行内存较高,需要8G内存以上的设备才能运行。
2024-08-07 03:47:59
腾讯课堂也要停止服务了,2016-2024
2024-08-08 06:25:51
OpenAI 发布 gpt-4o-2024-08-06 输出token提升3倍 降价33%-50% 支持JSON格式输出
2024-08-09 09:14:10
Google 播客将于 2024年8月30日停用,在此之前,您可以导出播客订阅,以便导入到您选择的服务中。 https://support.google.com/youtubemusic/answer/14151168
2024-08-09 10:54:59
刘海龙:媒介的三阶段 https://shop.vistopia.com.cn/article?article_id=570003&share_uid=gS0Ek
2024-08-10 09:08:41
抓娃娃,这不是楚门的世界吗
2024-08-11 16:08:02
巴黎奥运收官。
2024-08-17 03:56:57
中国游戏工业迎来里程碑时刻 《黑神话:悟空》全球媒体评分解禁 https://www.cnbeta.com.tw/articles/game/1442539.htm
2024-08-19 03:18:44
ollama本地运行qwen2,真简单
2024-08-20 03:15:45
https://store.steampowered.com/charts/mostplayed
2024-08-20 13:16:43
黑神话:悟空 Steam 最高同时在玩人数215.2万,超过幻兽帕鲁了
2024-08-24 00:47:37
三伏天结束。
2024-08-24 10:19:30
Apple Watch的米奇表盘居然可以点击报时(以前手表都是静音的所以没发现
2024-08-26 06:46:48
今年全球有10次载人航天发射任务:https://spacemission.vercel.app/
2024-08-28 02:12:36
由三体宇宙联合 PICO 出品的三体 VR 互动叙事作品《三体:远征》正式登陆 PICO 平台。玩家可以在 PICO 应用商店搜索《三体:远征》加入三体游戏,接收来自三体星系的的召唤,探索恒纪元、乱纪元的奥秘。
8月26日,高度还原《三体》原著中“三体游戏”内容的虚拟现实互动叙事作品《三体:远征》将上线。玩家将佩戴上“V装具”进入书中的三体游戏世界。据了解,《三体:远征》由PICO和三体宇宙出品,三体宇宙制作。
2024-08-28 13:05:31
新教材对一些表述的调整
2024-08-30 05:10:03
QQ手机客户端也内置了微信小程序基础库,可以直接运行微信小程序了
2024-08-30 05:12:47
国内对于基座大模型市场争夺,主要是各家云厂商提供便捷化配置型产品(比如appbuilder/百炼/元器),和提供自家和别家开源模型快捷部署服务等形式。
9月
2024-09-05 01:28:07
https://www.shapeof.ai
2024-09-07 01:19:57
Boeing‘s Starliner undocking from ISS without crew.
2024-09-09 17:15:19
Watch S10终于变薄了
2024-09-10 01:42:47
Watch S10国行版本不支持快充和呼吸暂停检测功能
2024-09-10 09:28:52
SpaceX launch the FIRST commercial spacewalk, Polaris Dawn https://www.youtube.com/watch?v=gWOYQ5Dto7c
2024-09-10 14:54:13
新华网新闻稿中出现的翻译:脸书母公司“元”(meta);谷歌旗下公司“深层思维”(deepmind);法国AI创企“米斯特拉尔人工智能”(Mistral AI);
央视报道中出现的翻译:人工智能公司“抱抱脸”(huggingface)
2024-09-12 06:53:17
Endpoint,有翻译为「终结点」的,有翻译为「端点」的
2024-09-13 00:09:34
体验了OpenAI最新的大模型o1-preview(🍓),每次回答都会把推理/思考过程列出来,但实际效果并没有超出预期,不知道正式版会不会好一些。目前Plus用户限制每周30条(o1-preview)和50条(o1-mini)。
2024-09-14 01:43:09
多邻国终于不是感冒的绿鸟了😂
2024-09-15 12:47:00
微信开发者工具教育版 提供基于混元大模型的AI编程助手,官方教程:https://developers.weixin.qq.com/community/business/course/00082803ba0ad06ce59d416545bc0d
2024-09-16 12:51:55
《中国计算机报》原执行总裁张永捷去世:生前患癌多年 https://m.cnbeta.com.tw/view/1445974.htm
2024-09-18 05:55:07
Microsoft 365(Office 365)Web版现在有3个域名:
office.com
microsoft365.com
m365.cloud.microsoft
2024-09-19 11:55:16
iOS18建议的壁纸挺不错
2024-09-21 15:16:29
玩了一下“Social AI”App,UI很像Threads,当你发布一条post之后,立即会有5条来自AI fans的评论,评论区继续往下滑会再来5条,评论风格各异,可以按照自己的喜好选择fans评论的风格。也算是另一种AI陪伴了😅
2024-09-23 05:28:05
继china.com邮箱之后,老牌电邮服务商tom.com邮箱本月27日清理免费邮箱数据,收费邮箱还会继续运营,最低是15元/月。
2024-09-25 04:11:40
在抖音刷到几个连麦听方言猜家乡的博主,通过听数字1-10、出去玩、外公外婆和一些关键词的方言说法,大部分都能精确到县,越是南方口音或者越是小众有特点的方言越被快速猜到。
2024-09-25 07:14:45
需要AI帮忙总结群聊内容
10月
2024-10-02 02:45:20
https://www.cnbeta.com.tw/articles/tech/1447696.htm
2024-10-02 02:46:48
https://m.cnbeta.com.tw/view/1447731.htm
2024-10-02 02:50:54
https://m.cnbeta.com.tw/view/1447744.htm
2024-10-02 02:51:46
https://m.cnbeta.com.tw/view/1447742.htm
2024-10-02 09:39:04
鸿蒙Next借鉴了许多iOS的优点,比如隐私控制和UI交互,这是智能手机和移动互联网发展15年来的一次规范重构的机会。
2024-10-04 02:14:24
power pages、glean、notebooklm、chatgpt canvas、claude artifacts都倾向于在一个workspace里完成辅助创作任务。
2024-10-04 15:12:22
Realtime API 两个Playground:
https://platform.openai.com/playground/realtime
https://playground.livekit.io
2024-10-09 12:43:49
诺贝尔化学奖应该直接颁给AlphaFold模型
2024-10-11 03:41:32
Cybercab、Robovan
2024-10-12 10:31:16
Flux Lora 模型「 Flux_小红书真实风格丨日常照片丨极致逼真」https://www.liblib.art/modelinfo/d9675e37370e493ab8bf52046827a2b0?from=search&versionUuid=7852ee527ca34d8b940d0749a75e4b67
2024-10-13 12:37:06
筷子夹助推器nb了 我在看科幻片
2024-10-15 15:02:21
“即使强如火箭,也要抱抱”
2024-10-18 02:20:05
Ollama+OpenWebUI就是目前最好的本地大模型方案
2024-10-19 15:20:25
微信webview开始在标题栏显示网页域名。
2024-10-20 08:59:51
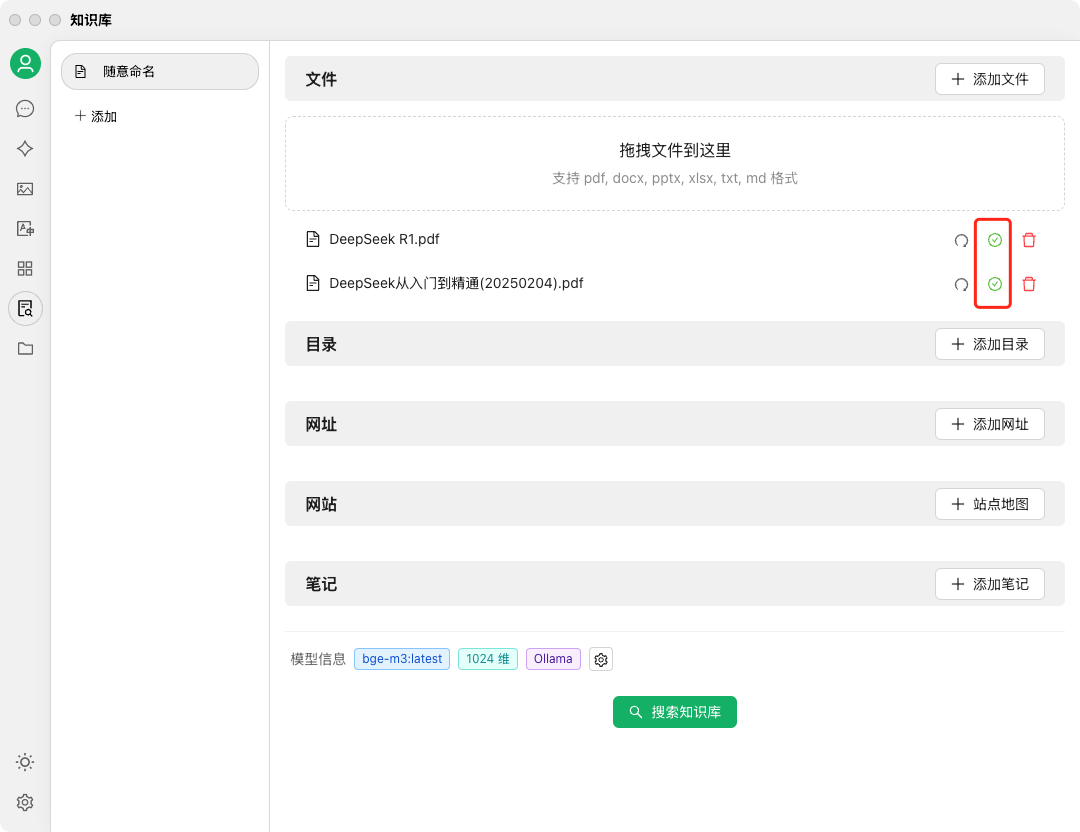
OneKey Card 服务逐步下线👋
2024 年 9 月 30 日起,将不再接受新的注册和充值。
2024 年 10 月 31 日,所有余额将安全转入您的钱包,并可随时提现。
2025 年 1 月 31 日,OneKey Card 服务将正式停止。
2024-10-21 02:18:39
人人网现在只剩关注页还能加载出数据了。。
2024-10-25 03:07:08
Cursor还能直接用来进行代码目录的语义化搜索,比如直接@codebase询问某模块的代码在哪里
2024-10-25 08:16:27
智谱开源端到端语音模型 https://github.com/THUDM/GLM-4-Voice
2024-10-28 00:36:48
崔永熙nba常规赛首秀替补登场2分钟,得分1分,加油!
2024-10-28 01:22:30
无论路上有没有车,在户外步行或骑行时都不要使用手机,要随时注意周围的情况。
2024-10-28 08:51:31
国行iPhone15 Pro系列、16系列、M芯片iPad Pro系列在iOS 18.2 Beta 使用Apple Intelligence的教程
https://t.me/s/TestFlightCN/28298
2024-10-29 01:58:33
神舟十九号任务有两位90后航天员,其中一位是女性。
2024-10-30 01:00:16
小米星辰无网通功能需在通话APP中使用,使用该功能前需插入SIM卡并登录小米账号;
数据来源于小米实验室,以上数据在内蒙古自治区乌兰察布市察哈尔右翼前旗草原(空旷、无遮挡、无干扰情况下)进行测试。
2024-10-30 11:11:11
鸿蒙AppGallery,迅雷和B站的更新记录里都提到了PC端,看起来全部鸿蒙应用都是Universal的
2024-10-30 11:23:11
https://www.nytimes.com/news-event/2024-election
https://decisiondeskhq.com/results/2024/General/President
https://www.politico.com/2024-election/results
https://edition.cnn.com/us
https://polymarket.com/elections
2024-10-31 12:07:03
在代码生成方面,Claude的口碑已经超过GPT
11月
2024-11-01 01:33:50
来自纽约的The Browser Company宣布停止Arc浏览器的开发。我其实也一直没有切到Arc做主力浏览器,试了几次又回到了Chrome。但真的很喜欢pin的常用webapp
2024-11-05 12:39:15
fox news在直播投票日情况了
2024-11-06 10:48:39
btc新的史高
2024-11-06 15:53:57
上古软件仓: https://skywind.me/wiki/%E4%B8%8A%E5%8F%A4%E8%BD%AF%E4%BB%B6%E4%BB%93
2024-11-07 03:31:00
万斯以前是作家,84年的,今年才40岁。这次川普万斯团队背后有硅谷投资人彼得蒂尔和马斯克的支持。传统上硅谷精英都是民主党的支持者,但也苦民主党久矣,这届川普政府感觉会是共和党内的新力量。
2024-11-08 11:06:48
微信收藏的搜索功能需要一个AI助手
2024-11-09 17:03:51
今年很多大型赛事的主色都用了紫色:钻石联赛、WTT、巴黎奥运会田径、WTA总决赛
2024-11-10 14:14:42
再次吹爆Claude,在软件和代码领域完全碾压ChatGPT
2024-11-11 14:41:03
多邻国的小听力练习做成了莉莉主持的podcast 有意思
2024-11-12 03:15:50
博通宣布 VMware Workstation 和 Fusion 彻底免费,支持商用
2024-11-13 01:36:04
DOGE起飞
2024-11-14 16:21:28
世预赛国足险胜巴林,两连胜小组排名第四
2024-11-17 06:37:47
SmartisanOS 8的字体实在是太好看了(翻出来再吸吸)
2024-11-21 03:22:58
Windsurf新王登基
2024-11-23 03:48:02
HBO Max登陆亚洲市场,有中文字幕了!
2024-11-24 15:08:05
还是在TL刷到了台湾今晚拿到的棒球世界冠军,大陆一点消息都看不到
2024-11-25 00:55:53
珍惜每一次btc回调机会,10万是共识
2024-11-25 07:42:08
Cursor更新到0.43
2024-11-25 08:21:25
多健康平安活一天 就是多成功了一天
2024-11-26 08:10:12
Mate70系列出厂搭载鸿蒙4.3,到手不用申请可直接升级5.0,明年发布的手机出厂搭载5.0。
2024-11-27 02:59:30
网易小蜜蜂,像素级对齐小红书……
2024-11-27 05:54:11
真理是不会只属于一个人的,最终它会被每个人发现。
2024-11-29 14:59:59
今天大陆媒体报道马龙到访的是“台湾文化大学”😂 这个反而不敢叫本名“中国文化大学”了🧐
2024-11-30 08:51:01
ChatGPT上线两周年。
12月
2024-12-01 02:14:20
看机器人之梦看得好难过
2024-12-01 15:04:29
https://mp.weixin.qq.com/s/ORX9rk8bTwvZNI0GhxRuKg
2024-12-02 05:37:54
又要开始年度总结了。
2024-12-04 06:44:29
这个收藏单出圈了:https://neodb.social/collection/2lYCXSioZK0RbaS3PG0k0s
2024-12-06 00:43:57
200刀的ChatGPT订阅来了
2024-12-09 10:16:30
中国上一次实施“适度宽松的货币政策”,还是胡温时期。
2024-12-10 04:02:27
https://sora.com/explore/recent
看看这个效果,感觉跟2月份没太大区别,但有了Storyboard,更好控制生成了
2024-12-10 04:07:45
把Google Cloud和Google One订阅都取消了
2024-12-11 07:07:53
邪恶大鼠标这个名字有点可爱是怎么回事
2024-12-12 10:37:09
大部分时候要低能耗蛰伏,潜龙勿用
2024-12-13 02:00:39
不去使用世界最先进的产品,就会固步自封。
2024-12-13 03:51:30
OpenAI关于昨天的事故分析报告:https://status.openai.com/incidents/ctrsv3lwd797
2024-12-13 06:59:15
Google — Year in Search 2024
VIDEO
2024-12-13 07:48:15
https://cn.nytimes.com/books/20241213/best-books-2024
2024-12-17 02:05:00
iPhone屏幕的色温真是每一台都不一样……(都关掉TrueTone的情况下
2024-12-18 13:36:17
iOS18了都还不能应用分屏 emmm这很难评
2024-12-19 00:42:27
把MacBookPro升级到15.2,Surface升级到24H2
2024-12-20 08:18:15
我的 #2024年度产品:
Claude
ChatGPT macOS客户端
Cursor
NotebookLM+Google AI Studio
Ollama+OpenWebUI
fullmoon+pocketpal
macOS15 iPhone镜像
扣子
欧易 Web3钱包
凤凰秀
2024-12-20 16:43:10
VIDEO
2024-12-23 06:29:20
用fullmoon在6GB内存的iPhone上用上了llama3.2-3b
https://fullmoon.app
2024-12-23 07:46:53
Google/Deepmind还是没有掉队,甚至坐二望一:
Gemini 2.0 Flash
https://aistudio.google.com
Imagen 3
https://labs.google/fx/zh/tools/image-fx
Veo 2
https://labs.google/fx/zh/tools/video-fx
2024-12-24 14:02:41
微信-我-设置-个人信息收集清单-图片与视频/位置
这里相当于是“微信年度总结”了
(仅支持绑定中国大陆手机号的微信帐号,WeChat不支持)
2024-12-24 15:10:45
http://share.fengshows.com/video.html?id=0c7081cd-e116-4298-851b-76916e932d6f&channelID=r06
2024-12-24 16:27:45
https://www.bilibili.com/video/BV1ttk9YkEVx
2024-12-24 16:49:24
闪极A1眼镜的排产已经到25年11月了……
2024-12-27 02:22:51
https://movie.douban.com/annual/2024/?fullscreen=1
2024-12-30 03:09:23
有了AI生成代码之后,做的工具形态更多了,从网站/app到browser插件、userscript、bookmarklet……